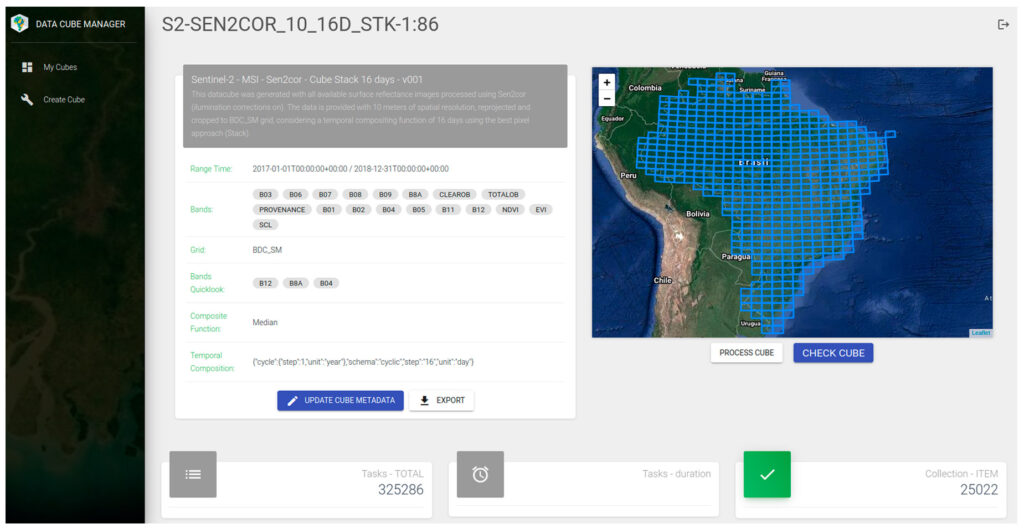
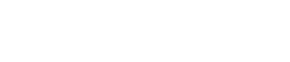Data Cube Builder consiste no conjunto de ferramentas para geração dos cubos de dados de observação terrestre sob demanda em ambiente local ou em nuvem AWS.
O procedimento Warp consiste em recortar e mosaicar espacialmente todas as imagens de entrada que se sobrepõem a um tile alvo da grade comum, para uma data específica. Este mosaico espacial é reprojetado para o sistema de referência do tile alvo e todas as bandas são reamostradas para uma determinada resolução espacial por meio de uma função bilinear, exceto para a banda de avaliação de qualidade, que é reamostrada usando o vizinho mais próximo para evitar alterações nos valores da imagem. O produto resultante é conhecido como Cubo Identidade.
Além disso, o Cube Builder oferece funções de composição temporal, que permitem gerar produtos compostos regulares no espaço e no tempo. A função mais comum é o Stack (STK), que consiste em utilizar o valor da imagem com maior área útil. Para isso, é feita uma ordenação das imagens de um período, por exemplo, 16 dias ou mensal, através da máscara de nuvem considerando observações válidas, ou seja, livre de nuvem ou sombra de nuvem conforme a imagem abaixo.
As funções de composições temporais no tempo suportadas pelo Cube Builder podem ser encontradas em Temporal Compositing Function
No final da geração dos cubos de dados, o Cube Builder calcula os índices de vegetação NDVI e EVI, bem como bandas que permitem identificar as características de geração do cubo de dados composto, são elas:
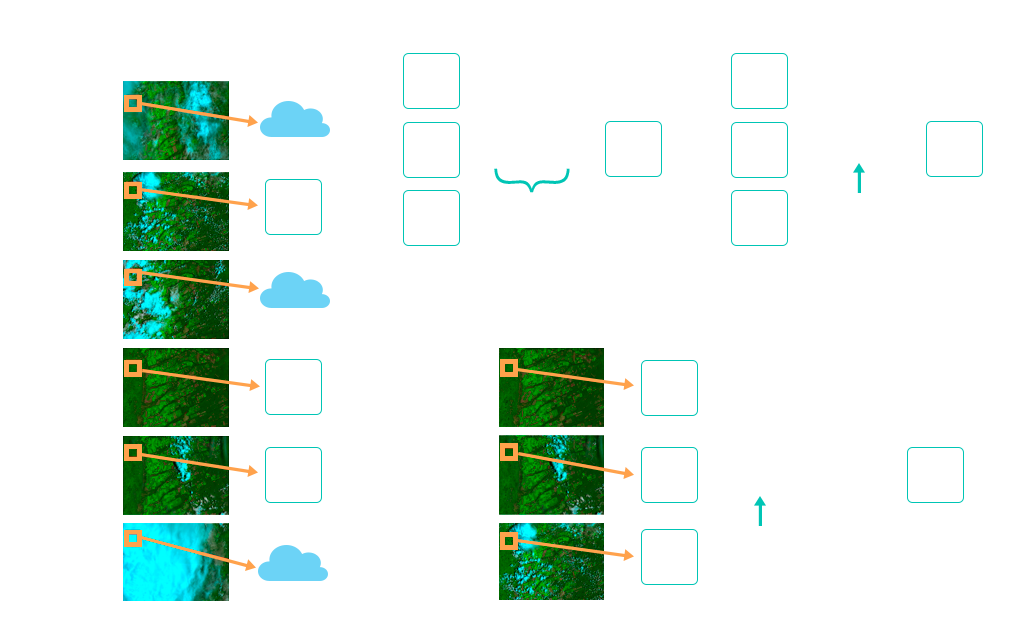
Arquitetura do Cube Builder na AWS
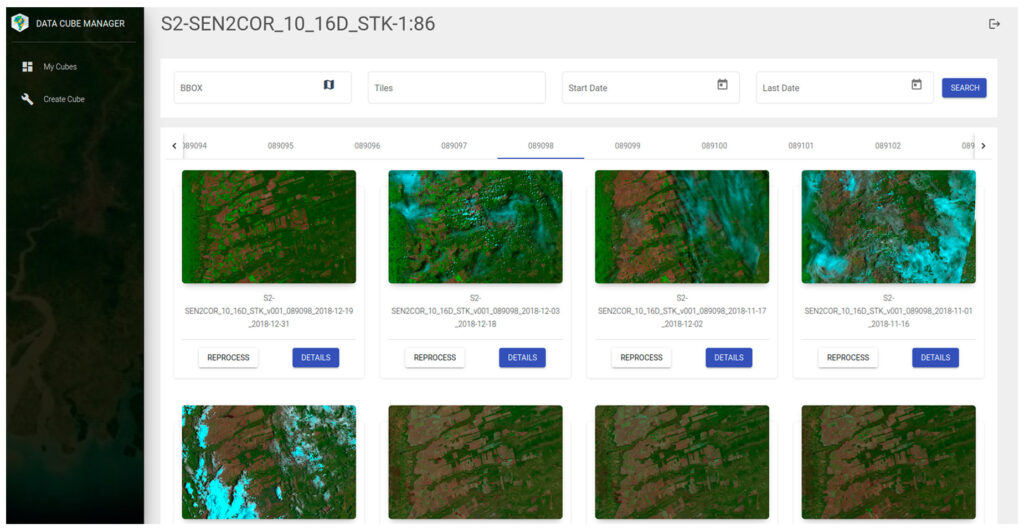
Galeria de Imagens
Publicações associadas

A equipe do Brazil Data Cube acaba de registrar quatro sistemas de software desenvolvidos no projeto no Instituto Nacional da Propriedade Industrial (INPI). O número de sistemas computacionais registrados no INPI é um dos indicadores de produtividade do INPE e de seus cursos de pós-graduação. Os sistemas registrados foram: (1) Web Time Series Service (WTSS): …